
report.md 16 KB
Datacenter Network Simulation using ns3实验报告
陈翊辉
SA19011116
[toc]
网络结构和参数
网络结构和参数如图1

图1 网络结构及参数图
inter-cluster

图2 inter-cluster连接示意图
many-to-one
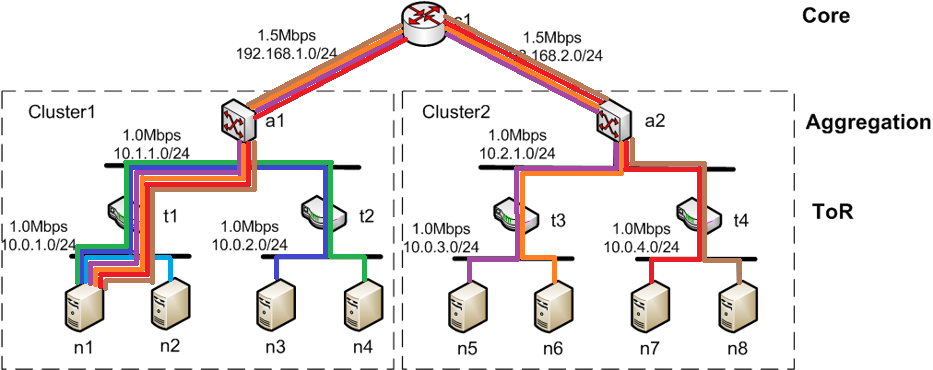
图2 many-to-one连接示意图
目录组织说明
- img:网络结构图,trace结果统计图
- pcap:抓包文件
- src:源码
report:报告
├── img │ ├── 1_2-3_2_rtt.png │ │ ... │ ├── many-to-one_trace.png │ └── opt │ ├── 2_2-4_2_rtt.png │ │ ... │ └── 3_3-1_2_th.png ├── pcap │ ├── inter-cluster │ │ ├── inter-cluster_merged.pcap │ │ ├── inter-cluster-10-0.pcap │ │ ├── inter-cluster-11-0.pcap │ │ ├── inter-cluster-13-0.pcap │ │ └── inter-cluster-8-0.pcap │ ├── many-to-one │ │ └── Many-to-one-7-0.pcap │ └── opt │ ├── inter-cluster │ │ ├── inter-cluster-11-0.pcap │ │ ├── inter-cluster-12-0.pcap │ │ ├── inter-cluster-14-0.pcap │ │ └── inter-cluster-9-0.pcap │ └── many-to-one │ └── inter-cluster-8-0.pcap ├── report.pdf └── src ├── inter-cluster.cc ├── inter-cluster-opt.cc ├── many-to-one.cc └── many-to-one-opt.cc
源码说明
基本参照课上slidesns3-Tutorial.pptx的几个ppp和ethernets及tcp例子组合即可。
代码使用Google Code Format规范,需要支持gnu std c++14编译器编译
完整代码见src/
首先定义各类节点数量,添加节点
const int CORE_SWITCH_NUM = 1;
const int AGGREGATION_NUM = 2;
const int TOR_NUM = 4;
const int SERVER_NUM = 8;
// ......
// core_switch | aggregation_switch | tor_switch | server
// 0 | 1 - 2 | 3 - 6 | 7 - 14
all_nodes.Create(CORE_SWITCH_NUM + AGGREGATION_NUM + TOR_NUM + SERVER_NUM);
根据网络结构,将要用p2p连接的节点加入p2p_nodes
// p2p link
p2p_nodes[i][j].Add(all_nodes.Get(i + CORE_THRESHOLD));
p2p_nodes[i][j].Add(all_nodes.Get(j + AGGREGATION_THRESHOLD));
使用PointToPointHelper增加p2p网络
netdev_core_aggr[i * AGGREGATION_NUM + j] = p2p_helper[i][j].Install(p2p_nodes[i][j]);
(csma节点类似,略)
用Ipv4InterfaceContainer分配3种ip地址
std::stringstream ss;
ss << "10.0." << i + 1 << ".0";
std::string base_addr;
ss >> base_addr;
addr.SetBase(base_addr.data(), "255.255.255.0");
安装网络应用sink和client,这里,使用sink-client对规定传输pattern
pattern1: inter-cluster
// sink - client settings idx: 1 - 8
// sink app nodes: 2, 4, 5, 7
// | | | |
// client app nodes: 6, 8, 1, 3
const std::vector<std::pair<int, int>> sink_client_pairs = {
{2, 6}, {4, 8}, {5, 1}, {7, 3}};
pattern2: many-to-one
// sink - client settings idx: 1 - 8
// sink app nodes: 1, 1, 1, 1, 1, 1, 1
// | | | | | | |
// client app nodes: 2, 3, 4, 5, 6, 7, 8
const std::vector<std::pair<int, int>> sink_client_pairs = {
{1, 2}, {1, 3}, {1, 4}, {1, 5}, {1, 6}, {1, 7}, {1, 8}};
这样两种pattern代码基本可以复用,只需修改sink-client对
PacketSinkHelper packetSinkHelper(
"ns3::TcpSocketFactory",
InetSocketAddress(Ipv4Address::GetAny(), 8080));
OnOffHelper onOffHelper(
"ns3::TcpSocketFactory",
InetSocketAddress(
tor_server[sink_idx / 2].GetAddress(sink_idx % 2 + 1), 8080));
最后在sink端启用trace,csma混杂模式为false
仿真结果及分析
inter-cluster
trace结果

图 2-6 节点 tcp抓包结果
以2-6的抓包为例,开始几个即ARP包用以确定对方mac地址,其后即两方来回tcp包,每个分包的长度有606,70等。
往返时间

图 2-6 节点间往返时间图
2-6之间的往返时间(rtt)很不稳定,较多序列(sequence)的往返时间很小(<10ms),但也有许多往返时间达到50多ms,100多ms,甚至少量达到了200多ms。
吞吐量与窗口大小

图 2-6节点间吞吐量及分片长度图
2-6之间的吞吐量也非常不稳定,在50kbits/s到500kbits/s之间上下振荡。
总体结果
| 测量 | 已捕获 | 已显示 |
|---|---|---|
| 分组 | 4400 | 4400 (100.0%) |
| 时间跨度,s | 61.285 | 61.285 |
| 平均 pps | 71.8 | 71.8 |
| 平均分组大小,B | 413 | 413 |
| 字节 | 1819396 | 1819396 (100.0%) |
| 平均 字节/秒 | 29 k | 29 k |
| 平均 比特/秒 | 237 k | 237 k |
表 2-6节点间抓包结果
总体上说,2-6之间达到的平均速率为237kbtits,而从rtt和吞吐来看,比较不稳定。
4-8,5-1,7-3之间的trace结果与2-6类似,往返时间和吞吐图见img/,总体结果如表
| 平均分组大小,字节 | 字节 | 平均 比特/秒 | |
|---|---|---|---|
| 2-6 | 413 | 1819396 | 237 k |
| 4-8 | 414 | 1873482 | 244 k |
| 5-1 | 414 | 1858744 | 242 k |
| 7-3 | 414 | 1893156 | 247 k |
表 inter-cluster抓包总体结果
网络瓶颈分析
从理论上分析,在cluster间通信,如图2 many-to-one连接示意图,在core switch的链路上,每条链路平均分到1.5mbps的$\frac{1}{4}$,即大约375kbps;在aggregation switch到tor switch的链路上,每条链路平均分到1.0mbps的$\frac{1}{4}$,即大约250kbps,因而要full bisection使每台server达到1mpbs,瓶颈在aggregation switch到tor switch的链路上和core switch的链路上。从仿真结果来看,平均每对节点间的速率为243kbps左右,由此计算出a1和a2链路上速率为970kbps左右,以达到线路带宽上限,与理论符合较好。即aggregation switch链路上确实存在瓶颈。
many-to-one
trace结果

和inter-cluster类似,还是先arp找mac地址,之后tcp通信。
| 测量 | 已捕获 | 已显示 |
|---|---|---|
| 分组 | 20136 | 20136 (100.0%) |
| 时间跨度,s | 67.446 | 67.446 |
| 平均 pps | 298.5 | 298.5 |
| 平均分组大小,B | 408 | 408 |
| 字节 | 8215218 | 8215218 (100.0%) |
| 平均 字节/秒 | 121 k | 121 k |
| 平均 比特/秒 | 974 k | 974 k |
表 many-to-one trace结果统计表
从节点n1来看,速率基本达到了n1链路的1mbps。
n2
n2(10.0.1.3)和n1接在同一tor上,其往返时间和吞吐及窗口大小如下

图 2-1 节点间往返时间图

图 2-1 节点间吞吐量和分片大小图
从上图可以看出,2-1节点间吞吐量相对稳定,在300-500kbps间;而往返时间开始时非常低(<20ms),之后逐渐升高,达到2000ms左右,仿真结束前回落到1200ms左右。
n3 n4
n3(10.0.2.2)和n4(10.0.2.3)和n1在同一cluster,以n3为例其往返时间和吞吐及窗口大小如下

图 3-1 节点间往返时间图

图 3-1 节点间吞吐量和分片大小图
从上图来看,3-1节点间吞吐量非常不稳定,在0和400000bps之前,而往返时间在开始是极低,之后增长到2000ms以上,在仿真结束前又回到极低。4-1节点与3-1节点类似,见img,不在报告中包含。
n5 n6 n7 n8
n5 n6 n7 n8节点在另一个cluster,以n5(10.0.3.2)为例其往返时间和吞吐及窗口大小如下
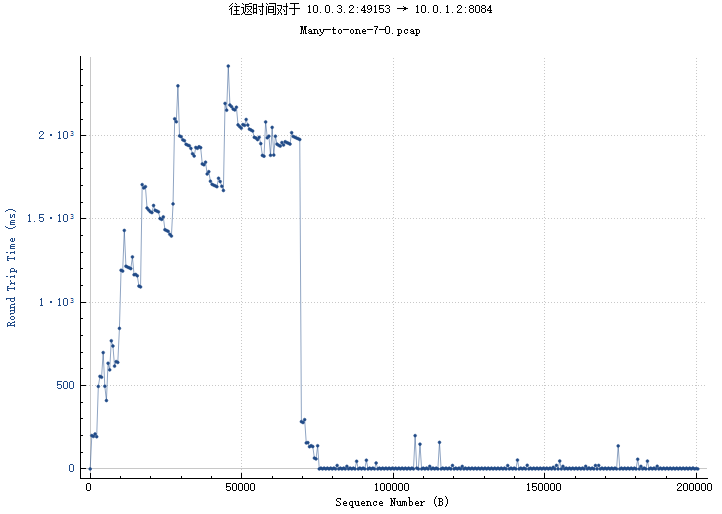
图 5-1 节点间往返时间图

图 5-1 节点间吞吐量和分片大小图
从上图来看,5-1节点间连接,在60s前几乎分不到带宽,往返时间在2000ms左右,在60s之后(n2 n3 n4都传输完了),分到几百kbps带宽,6,7,8节点结果见img,不在报告中包含。
总体结果
| Address A | Address B | Packets | Bytes | Bytes B → A | Duration |
|---|---|---|---|---|---|
| 10.0.1.2 | 10.0.1.3 | 8984 | 3692696 | 3482972 | 61.99544 |
| 10.0.1.2 | 10.0.2.3 | 2979 | 1236634 | 1166700 | 64.38073 |
| 10.0.1.2 | 10.0.2.2 | 3267 | 1355098 | 1278444 | 64.37938 |
| 10.0.1.2 | 10.0.4.2 | 3086 | 1235140 | 1165906 | 65.94691 |
| 10.0.1.2 | 10.0.4.3 | 625 | 240002 | 226554 | 67.40779 |
| 10.0.1.2 | 10.0.3.2 | 640 | 245136 | 231338 | 67.41691 |
| 10.0.1.2 | 10.0.3.3 | 547 | 210000 | 198236 | 62.92476 |
表 many-to-one trace结果统计表
从上表来看,离n1越近的吞吐越多。而5,6,7,8本来应该结果接近的,但其中7却获取了较多吞吐,这表明了网络可预测性不好,有较大波动和随机性。
网络瓶颈分析
从理论上分析,若2-7节点都要达到1mbps速率,则n1节点需要7mbps,t1需要6mbps,t2需要2mbps,c1,a2需要4mbps,t3,t4需要2mbps。总的来说,瓶颈主要还是在core到aggregation之间。从仿真结果来看,cluster2总的吞吐都不高,也是受限于core到aggregation之间。
优化方法
从上面分析上看,网络瓶颈主要在core到aggregation及aggregation到tor之间。因而考虑增加一个core switch;并且参考胖树结构,增加连通度,增加aggregation到其他tor的连接;并且使用ecmp路由。

优化源码说明
在之前代码基础上,只需做少量修改,具体见src/
另外需要说明的是,需要注释掉ns-3里一个和ecmp有关的assert(或者编release版本)
ns-allinone-3.27/ns-3.27/src/internet/model/global-route-manager-impl.cc +316
// NS_ASSERT_MSG (m_ecmpRootExits.size () <= 1, "Assumed there is at most one exit from the root to this vertex");
首先修改core switch 的数量
const int CORE_SWITCH_NUM = 2;
const int AGGREGATION_NUM = 2;
const int TOR_NUM = 4;
const int SERVER_NUM = 8;
aggregation到tor的csma连接增加
for (int i = 0; i < AGGREGATION_NUM; ++i) {
csma_aggregation_nodes[i * 2].Add(all_nodes.Get(AGGREGATION_THRESHOLD + i));
csma_aggregation_nodes[i * 2].Add(all_nodes.Get(TOR_THRESHOLD));
csma_aggregation_nodes[i * 2].Add(all_nodes.Get(TOR_THRESHOLD + 1));
csma_aggregation_nodes[i * 2 + 1].Add(all_nodes.Get(AGGREGATION_THRESHOLD + i));
csma_aggregation_nodes[i * 2 + 1].Add(all_nodes.Get(TOR_THRESHOLD + 2));
csma_aggregation_nodes[i * 2 + 1].Add(all_nodes.Get(TOR_THRESHOLD + 3));
}
使用ecmp路由
// Enable ECMP routing
Config::SetDefault("ns3::Ipv4GlobalRouting::RandomEcmpRouting", BooleanValue(true));
优化结果
优化的度量主要考虑往返时间,吞吐的大小和稳定性及各节点获得带宽的差距。
inter-cluster
总体比较
| 字节 - 优化前 | 平均 比特/秒 - 优化前 | 字节 - 优化后 | 平均 比特/秒 - 优化后 | |
|---|---|---|---|---|
| 2-6 | 1819396 | 237 k | 3911322 | 496 k |
| 4-8 | 1873482 | 244 k | 3425396 | 435 k |
| 5-1 | 1858744 | 242 k | 3135438 | 401 k |
| 7-3 | 1893156 | 247 k | 3551942 | 452 k |
表 inter-cluster优化前后吞吐对比
从上表可见,优化后吞吐明显提升,瓶颈变为tor到server链路带宽。
往返时间

图 优化后inter-cluster往返时间图
从上图来看,往返时间也有很大改善,大多数往返时间极端,最大也不超过100ms,极少数超过60ms。
吞吐及分片大小

图 优化后inter-cluster吞吐和分片长度图
从上图来看,分片长度非常稳定,而吞吐除了大幅提高外也较优化前稳定。其他几对连接结果也类似。
many-to-one
总体比较
| Address A | Address B | Bytes | Bytes-opt | Duration | Duration-opt | Bytes B → A | Bits/s B → A - opt |
|---|---|---|---|---|---|---|---|
| 10.0.1.2 | 10.0.1.3 | 3692696 | 3302192 | 61.99544 | 62.09534 | 3482972 | 401292.3 |
| 10.0.1.2 | 10.0.2.2 | 1355098 | 1048420 | 64.37938 | 66.19298 | 1278444 | 119081.9 |
| 10.0.1.2 | 10.0.2.3 | 1236634 | 360872 | 64.38073 | 68.13514 | 1166700 | 39450.31 |
| 10.0.1.2 | 10.0.3.2 | 245136 | 905990 | 67.41691 | 64.15984 | 231338 | 105996.8 |
| 10.0.1.2 | 10.0.3.3 | 210000 | 842802 | 62.92476 | 66.88895 | 198236 | 93787.21 |
| 10.0.1.2 | 10.0.4.2 | 1235140 | 938414 | 65.94691 | 66.20609 | 1165906 | 106482.3 |
| 10.0.1.2 | 10.0.4.3 | 240002 | 893610 | 67.40779 | 64.16249 | 226554 | 104477.5 |
表 many-to-one优化前后总部比较
从上表来看,优化后,总的带宽没有变化,大约为1mbps(因为节点的连接是1mbps),但相对于优化前,另一个cluster的4个节点传输的字节数非常均匀,每个节点的传输过程时尝也比较均匀。较原来有较大提升。
往返时间

从上图来看,在资源争夺阶段往返时间比优化前提高了,但也有较低的情况,原因是可以多条链路,有些链路通畅,而有些链路拥塞。而各个节点之前的差距比优化前减少了,也即提升了网络公平性。
吞吐

图 many-to-one优化后吞吐和分片长度
从上图来看,优化后整个过程中吞吐都比较均匀,虽然有某些时刻降到0,但没有出现长时间获取不到资源,也没有出现优化前前期几乎争不到资源的情况,只能等别的节点传完再开始的情况。而分片大小也非常稳定。
总结
使用了core switch和ecmp routing后,网络性能提升,特别是many-to-one这种情况,减少了网络的波动,增加了网络的公平性和可预测性。这比单纯提高带宽的效果要更好。并且增加core switch和链路数量后,网络的鲁棒性也提升了,即使某个核心或聚合交换机故障,网络也能连通。